Network of Transcript Semantics
I wrote an NLP-package for analysing the content of natural speech during my postdoc at the University of Cambridge.
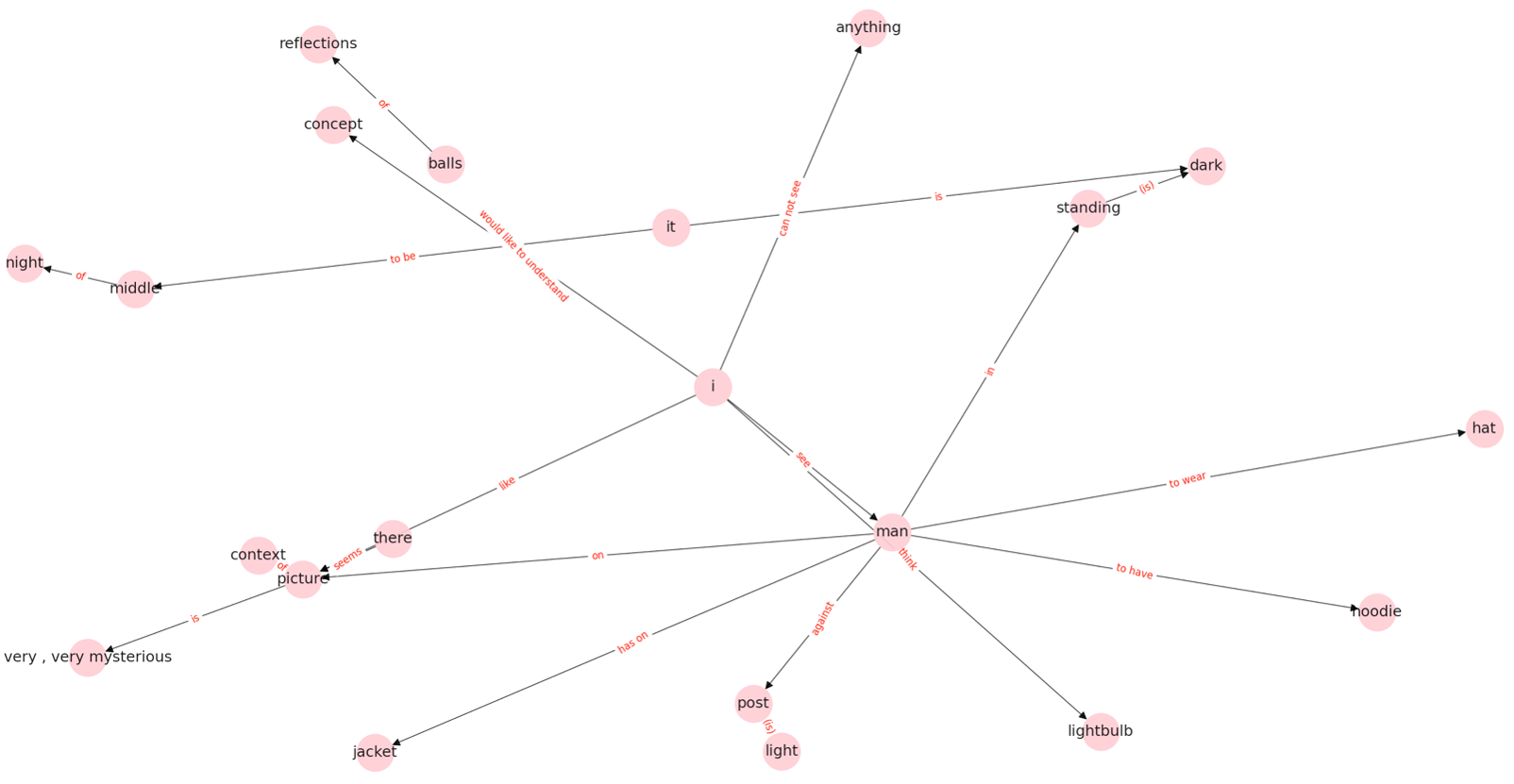
The algorithm (netts) constructs networks from a speech transcript that represent the content of what the speaker said. The idea here is that the nodes in the network show the entities that the speaker mentioned, like a cat, a house, etc. (usually nouns). And the edges of the network show the relationships between the entities.
We called these networks semantic speech networks.
Why did we want to represent speech content as a network? There is evidence that psychiatric conditions, in particular early psychosis (schizophrenia), can be traced early in abnormal language. In psychosis, there is a phenomenon called ‘loosening of associations’, where connection between ideas can become tenuous and extraneuous concepts seem to intrude into the line of thought. We hypothesised that mapping speech content as a network could capture this abnormal language features early in psychosis - potentially aiding diagnosis and disease monitoring. In a clinical sample of patients with early psychosis and controls, that was indeed the case (you can find the paper here).
We also believe that this tool could be useful for analysing speech content in other conditions and also in healthy and developing populations - the semantic speech networks are quite rich in information. If you’re interested in using semantic speech networks for your own data, we have written an installation guide. You can also use our interactive tutorials on creating and analysing semantic speech networks.
4. How does netts work?
Let’s quickly walk through how netts works. This is more extensively covered in our paper, but briefly reviewing the processing steps will help us understand the semantic speech networks.
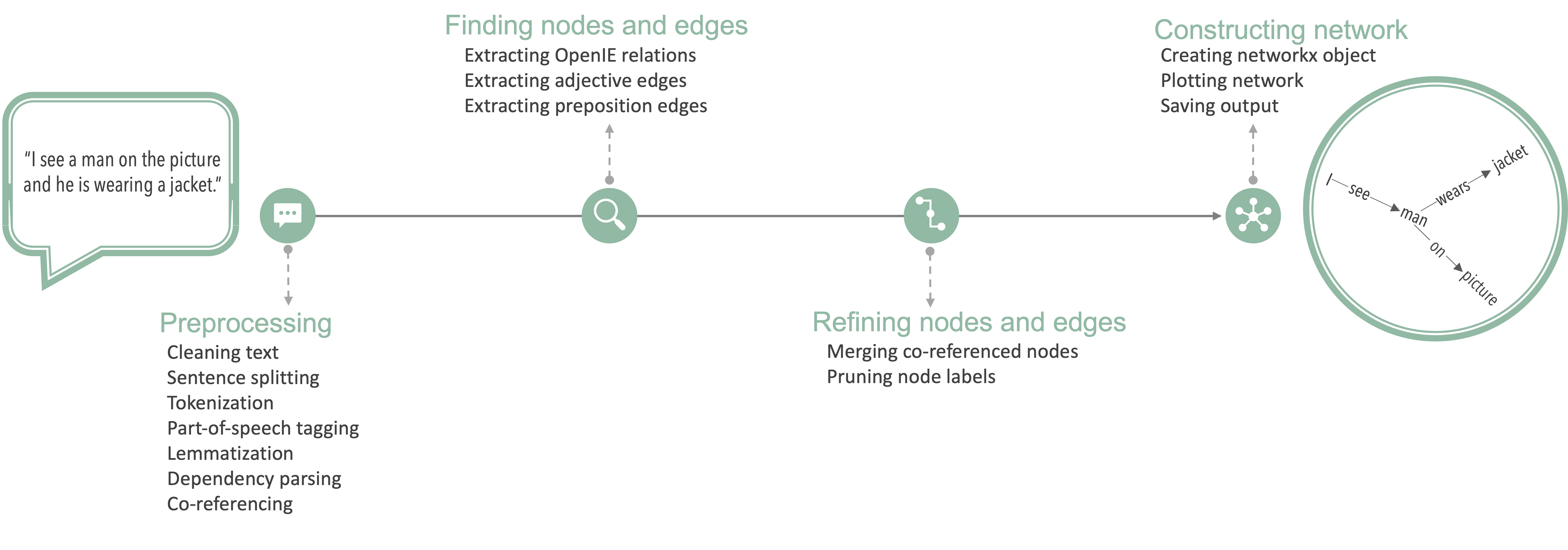
Preprocessing
Netts first expands the most common English contractions (e.g. expanding I’m to I am). It then removes interjections (Mh, Uhm). Netts also removes any transcription notes (e.g. timestamps, [inaudible]) that were inserted by the transcriber. The user can pass a file of transcription notes that should be removed from the transcripts before processing. See Configuration for a step-by-step guide on passing custom transcription notes to netts for removal. Netts does not remove stop words or punctuation to stay as close to the original speech as possible.
Netts then uses CoreNLP to perform sentence splitting, tokenization, part of speech tagging, lemmatization, dependency parsing and co-referencing on the transcript. Netts uses the default language model implemented in CoreNLP.
We describe these Natural Language Processing steps briefly in the following. The transcript is first split into sentences (sentence splitting). It is then further split into meaningful entities, usually words (tokenization). Each word is assigned a part of speech label. The part of speech label indicates whether the word is a verb, noun, or another part of speech (part of speech tagging). Each word is also assigned their dictionary form or lemma (lemmatization). Next, the grammatical relationship between words is identified (dependency parsing). Finally, any occurrences where two or more expressions in the transcript refer to the same entity are identified (co-referencing). For example where a noun man and a pronoun he refer to the same person.
Finding nodes and edges
Netts submits each sentence to OpenIE5 for relation extraction. Openie5 extracts semantic relationships between entities from the sentence. For example, performing relation extraction on the sentence I see a man identifies the relation see between the entities I and a man. From these extracted relations, netts creates an initial list of the edges that will be present in the semantic speech network. In the edge list, the entities are the nodes and the relations are the edge labels.
Next, netts uses the part of speech tags and dependency structure to extract edges defined by adjectives or prepositions: For instance, a man on the picture contains a preposition edge where the entity a man and the picture are linked by an edge labelled on. An example of an adjective edge would be dark background. Here, dark and background are linked by an implicit is. These adjective edges and preposition edges are added to the edge list. During the next processing steps this edge list is further refined.
Refining nodes and edges
After creating the edge list, netts uses the co-referencing information to merge nodes that refer to the same entity. This is to take into account cases different words refer to the same entity. For example in the case where the pronoun he is used to refer to a man or in the case where the synonym the guy is used to refer to a man. Every entity mentioned in the text should be represented by a unique node in the semantic speech network. Therefore, nodes referring to the same entity are merged by replacing the node label in the edge list with the most representative node label (first mention of the entity that is a noun). In the example above, he and the guy would be replaced by a man. Node labels are then cleaned of superfluous words such as determiners. For example, a man would turn into man.
Constructing network
In the final step, netts constructs a semantic speech network from the edge list using networkx. The network is then plotted and saves the output. The output consists of the networkx object, the network image and the log messages from netts. The resulting network (a MultiDiGraph) is directed and unweighted, and can have parallel edges and self-loops. Parallel edges are two or more edges that link the same two nodes in the same direction. A self-loop is an edge that links a node with itself.
If you would like to learn how to use netts to create semantic speech networks, have a look at my walk through creating and analysing semantic speech networks.
Links


Documentation: https://alan-turing-institute.github.io/netts/
Source Code: https://github.com/alan-turing-institute/netts
Media Coverage: Medscape Article
Contributors
Netts was written by Caroline Nettekoven in collaboration with Sarah Morgan.
Netts was packaged in collaboration with Oscar Giles, Iain Stenson and Helen Duncan.
Caroline Nettekoven
Wellcome Early Career Fellow
I am interested in the neural basis of complex behaviour. To study this, I use neuroimaging techniques, computational modelling of behaviour and brain stimulation.